中古不動産価格の予測モデル作成の続きです。
前回までの記事で不動産取引価格情報の取得と機械学習用のデータの前処理について紹介させていただきました。今回から回帰モデル作成の事例について紹介します。まずscikit-learnで利用可能な回帰モデルでの実装を検討してみました。
以下は必要なライブラリーのインポートです。以前の記事でも紹介しましたが、可能な回帰モデルをできるだけ多く読み込んで、それらの結果を比較してよさそうなものにあたりをつけようという感じです。今回も以下の記事を参考にさせていただきました。

さらにそれぞれの回帰モデルを網羅的に処理していくために辞書型のリストで整理しています。この辺も以前の電気料金の予測モデル作成の記事で紹介させていただきました。

続いて、前回に紹介したデータの前処理です。不動産情報の読み込みと築年数の算出の処理を行っています。尚、今回は種々のモデルでの結果を比較するため、各モデルの精度の保存先のリストも予め作成しています(下記3行目)。

建築年数と取引年から築年数を算出し、さらにdropna()を実行して欠損値処理を行っています。最終的に回帰モデル作成用の目的変数として「取引価格」、説明変数として、「最寄り駅からの距離」、「間口」、「面積」などを設定しています。

以上で、モデル検討用のデータセットが準備できたので、コード5〜7で各種回帰モデルでの実際の検討と結果の表示を行っています(この辺は以前の電気料金の予測モデル作成の記事と同様です)。



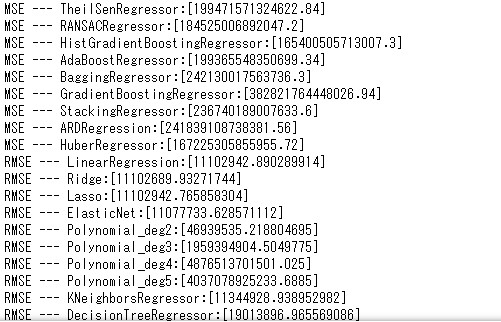
以下は得られた結果の一覧です。訓練データのR2値が良好なものもありますが、テストデータでは必ずしも良い結果は得られませんでした。これらの回帰モデルの中から使えそうなものをピックアップしていくことになるのですが、今回はハイパーパラーメータのチューニングの練習の意味も含めて、Ababoost法(あまり良い結果は得られていませんが)での検討をさらに行ってみることにしてみました。次回以降、ハイパーパラメータの最適化条件の検討について紹介したいと思います。