前回の記事で、「暑さ指数」と「気象データ」の相関について、リニアモデルでの機械学習モデルの作成について、紹介しました。今回はハイパーパラメーターの設定の検討のため、SVR(Support Vector Regression,サポートベクター回帰)でのモデル作成を検討しました。

まずは、Pandas, Numpyなど一般的なものに加えて、SVRの実施と、評価、ハイパラメーター検討に必要なライブラリー(今回はランダムサーチ)を読み込みます。

続いて前回と同様に、作成したデータ(csv形式)をpandas のデータフレームとして読み込み、学習用の目的変数(y)としてWBGT、説明変数(x)として、Tg, Temp, windm air press, humidity, rainfall, sunshineをデータフレームから抽出しています。

続いて、データのスケールを揃えるため、それぞれの説明変数の標準化の処理をおこなっています。

SVRでは、主として3種類のハイパーパラメータ(カーネル関数、正則化係数C、不感度係数ε)がありますので、それらの変化の範囲を設定します。今回はランダムサーチで15回ハイパーパラメーターのサーチを行うこととして、コードを作成しました。

続いて、ランダムサーチ時に作成したモデルの評価のため、それぞれ評価値の算出も行っています。

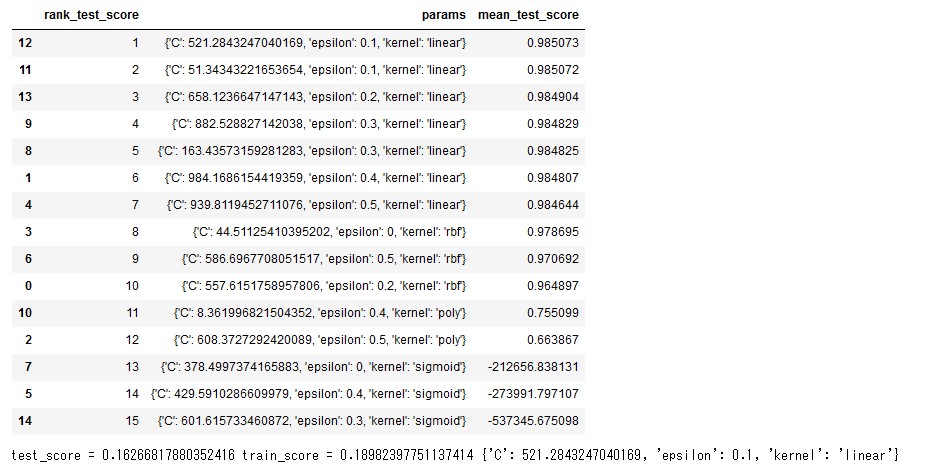
最終的にランダムサーチの結果はcv_resultsに辞書型で保存されますので、それらをデータフレームとした後、評価の良い順番にソートして結果を必要なデータ(ランキング、パラメーター、予測精度の平均)表示させています。
以下は実際にランダムサーチを行った結果です。ハイパーパラメータの値によっては評価値がばらついていますが、ランキングの良いモデルは非常に良い精度で予測モデルが作成できていることがわかります。
以上、今回はSVRでの機械学習モデルの作成とランダムサーチでのハイパーパラメーターの検討事例について紹介させていただきました。次回はまた異なった手法でのパイパーパラメーターの検討事例について紹介したいと思います。