前回までの記事で我が家の電気料金と気象情報との関係について、相関モデルの作成の検討を紹介してきました。残念ながらあまり良い相関モデルが作れませんでしたがので、実際に比較的良い相関がとれそうなもので検討してみようということで、環境省が公表している「暑さ指数」と気象庁の「気象データ」との相関について、検討を行ってみました。暑さ指数は熱中症予防を目的に提案された指標で観測される気象情報から算出される指標です。

暑さ指数について(環境省 HPから)
実際に暑さ指数(WBGT)は下記のような測定値から実測値や、気象庁の観測データから実況測定値が算出されています。

暑さ指数(WBGT)について (環境省HPから)

暑さ指数の算出の実際(環境省HPから)
今回は、機械学習モデル作成の練習として、入手可能な公開データから「暑さ指数」と「気象データ」と間での相関モデル作成の検討を行ってみました。
暑さ指数のデータは環境省から過去のデータが1時間ごとのデータとしてダウンロードできます。WBGTが暑さ指数のデータで、Tgが黒球温度の観測値を示しています。

暑さ指数データ(環境省から)
このデータに気象庁から気温、風速、気圧、湿度、降雨量、日照などのデータをダウンロードしたものを加えて、機械学習用データ(heatindex2020_04_plus_weather.csv)としました。(2020年4月、東京都のデータで作成しています:下記)

機械学習用データ(暑さ指数データ(環境省) + 気象データ(気象庁))
上記データに対して、まずはリニアモデルでの予測モデル作成の検討を行いました。

予測モデル作成コード その1
まずはPythonから必要ライブラリーの読み込みと、sklearn からリニアモデルや評価指標算出用のライブラリーを読み込みます。続いて作成したデータ(csv形式)をpandas のデータフレームとして読み込んでいます。
続いて学習用の目的変数(y)としてWBGT、説明変数(x)として、Tg, Temp, windm air press, humidity, rainfall, sunshineをデータフレームから抽出しています。

予測モデル作成コード その2
次に、モデル評価数値(R2,MSE,RMSE)及び相関係数(coefficient) 格納用のリストを作成しています。
for 文以下でモデル作成を5回トライしています。
続いて、作成したモデルでのそれぞれの評価数値の算出とリストへの格納を行っています。

予測モデル作成コード その3
最後に、格納したリストの平均値を算出するとともに、それぞれのトライアルでの相関係数のデータフレームを作成し、結果表示を行っています。

予測モデル作成コード その4
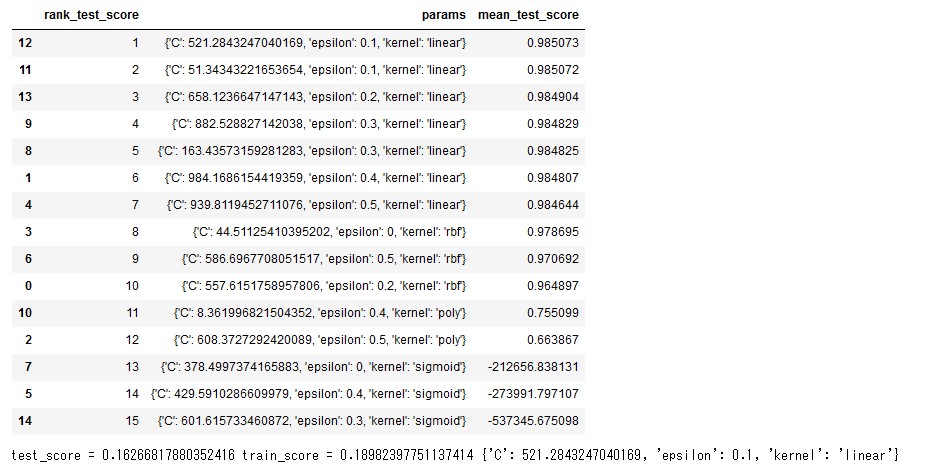
以下は2020年4月の東京でのデータについて予測モデル作成の検討を行った結果です。
訓練、テストデータいずれにおいても良好な決定係数を示す結果が得られています。暑さ指数のベースとなるデータを考えれば当然の結果といえば当然の結果かと思います。相関係数を確認すると温度と強い正の相関、日照時間と強い負の相関がみられ、こちらもある意味当然の結果といえるかもしれません。

予測モデルの作成結果
以上、機械学習モデル作成の練習として、暑さ指数のリニアモデルでの作成検討について、紹介させていただきました。
非常に相関性の高いデータですので、この結果だけでも学習モデルとしては十分かと思いますが、自身の勉強の意味で、他の学習モデルやハイパーパラメータ設定の検討なども行っていますので、それらの結果について、順次紹介できればと思います。